
Our Augmented Intelligence-powered Life Sciences Platform provides solutions to discover and develop safer and more successful medicines for patients
We harness proprietary Artificial Intelligence and Machine Learning to provide unprecedented causal insights from the global data universe comprising Life Sciences, human data and real world data. These causal insights capture the biological complexity of diseases and deliver therapeutic strategies to enable treatment of incurable diseases and transform development of effective medicines.
Our proprietary capabilities in Life Science Language Processing™ and Computer Vision contextualize multimodal data, discover non-obvious connections, and accelerate development of drugs and therapies from early stage drug discovery to commercialization irrespective of therapeutic area and modality.
Learn More
For large pharma, biotechs and CROs
In an era of global transformation, where scientific knowledge, human data and AI/ML shape the future of drug discovery and healthcare, our Ontosight® solutions support all stages of drug development from ideation to market. Ontosight® modules offer an unbiased, holistic and integrated approach to discover and develop medicines and therapies independent of therapeutic area, indication and modality.
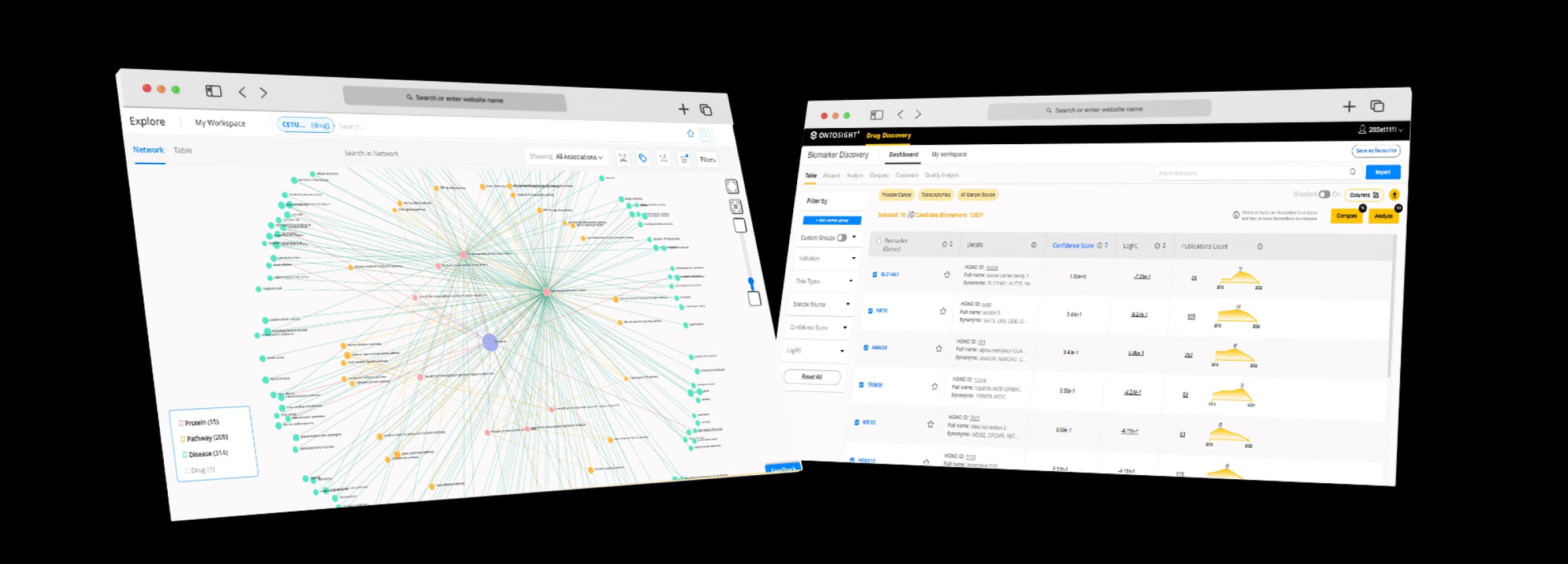
For large pharma, biotechs and CROs
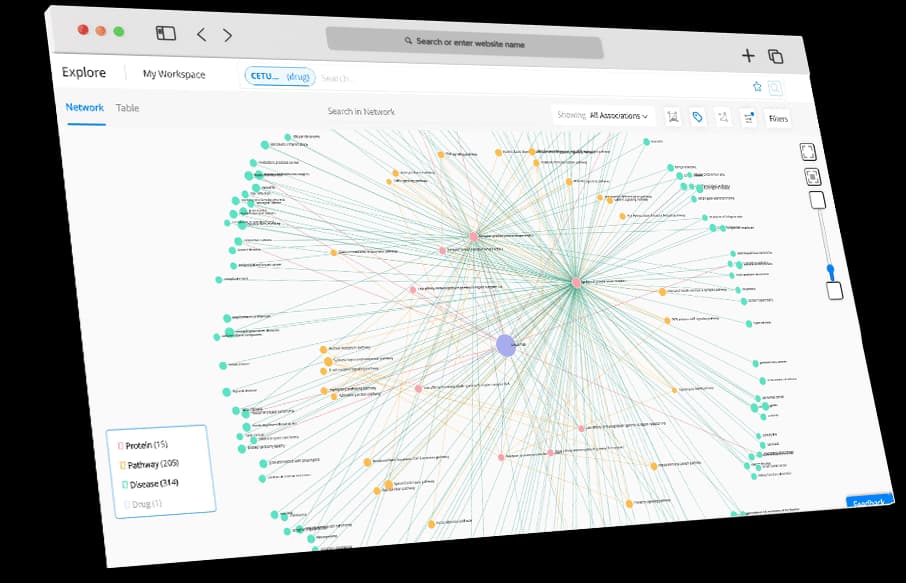
Scientific knowledge aggregation and mining platform that facilitates searching, screening and synthesizing information from all relevant, globally available sources of biomedical knowledge covering all life sciences disciplines. Visualize ‘never-thought-to-be-linked’ biological entities and pathophysiological concepts that underlie complex diseases to identify the Achilles’ heel of disease and build a tailored therapeutic strategy. Track over 23+ million researchers, investigators, and key opinion leaders (KOLs) globally.

For medical affairs, regulatory affairs, BD&L teams and clinical design teams.
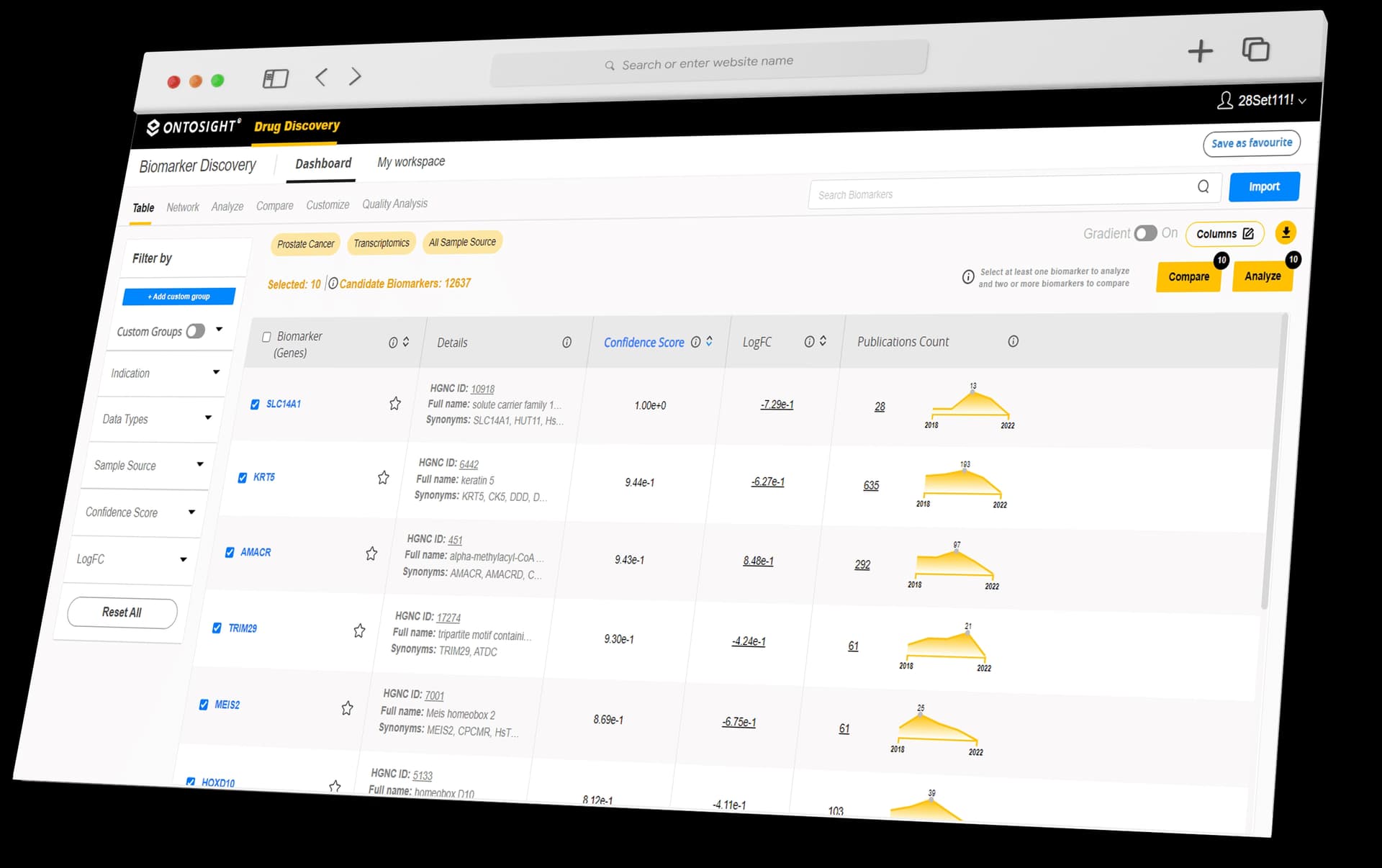
Clean, structure, consolidate and combine diversified and disparate datasets from various public, enterprise, third-party and other siloed sources to enable integrative data analysis. Automated analytics of developing and scaling data environments with tailored and intuitive visualization that enables decision-making.
Enabling Decentralized Science for equitable and efficient healthcare by leveraging AI and Blockchain technologies.

Receive tokens for providing data, can donate tokens, can buy in-app services with tokens, e.g., second opinion, digital therapeutics
Run surveys using tokens, pay tokens for participation, license data in and out

Can buy tokens on the secondary exchange and profit from the value increase
Receive donations, facilitate discovery and other programs for patients
* Tokens are not applicable to U.S. citizens.
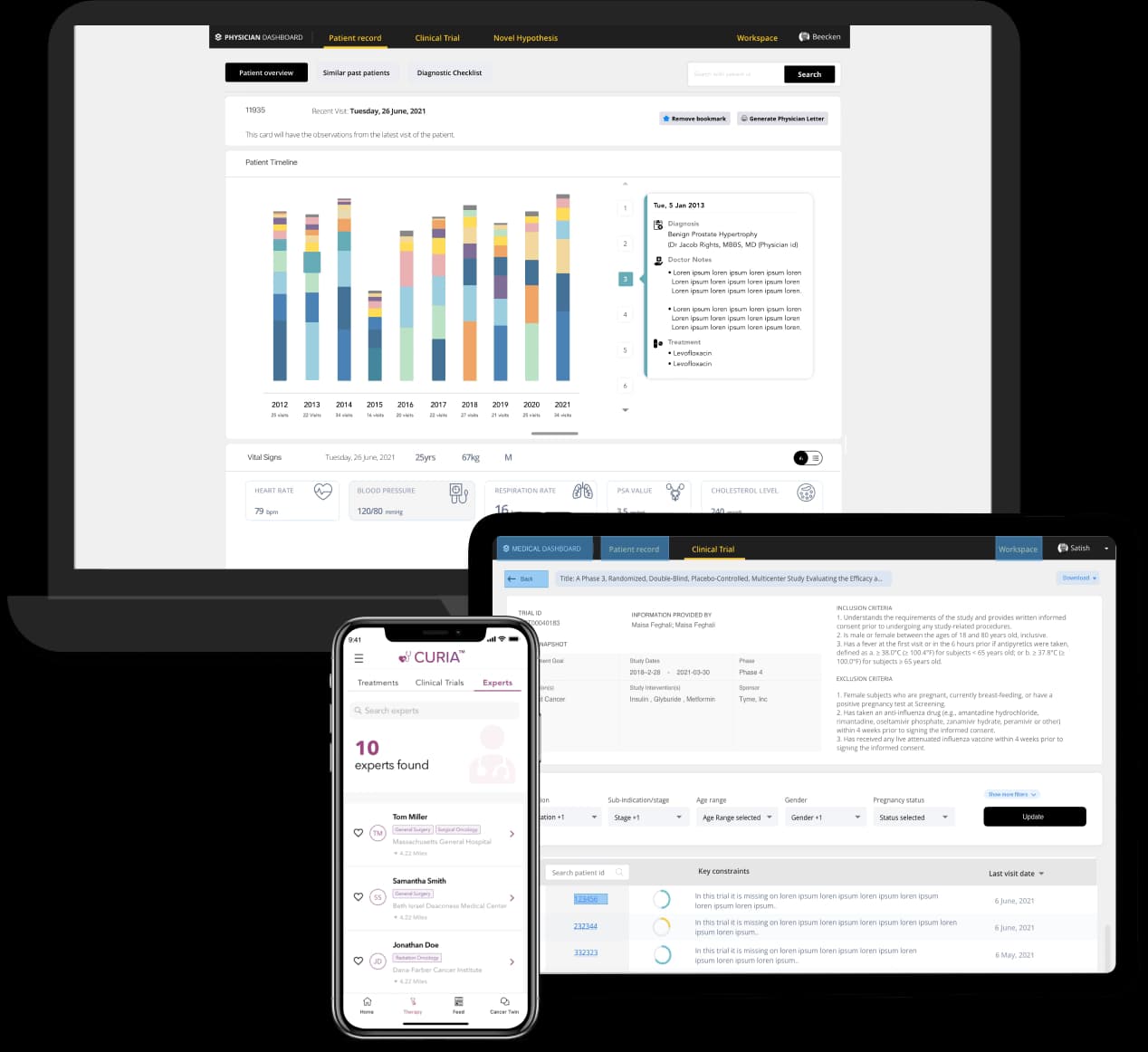
Hospital Dashboard CT Recruitment Patient App

48.9M+
Publications
830K+
Clinical trials
2.2M+
Congresses
4.6M+
Grants
1.5M+
Thesis & dissertations
200K+
Protein, gene & drugs
9.4M+
Patents
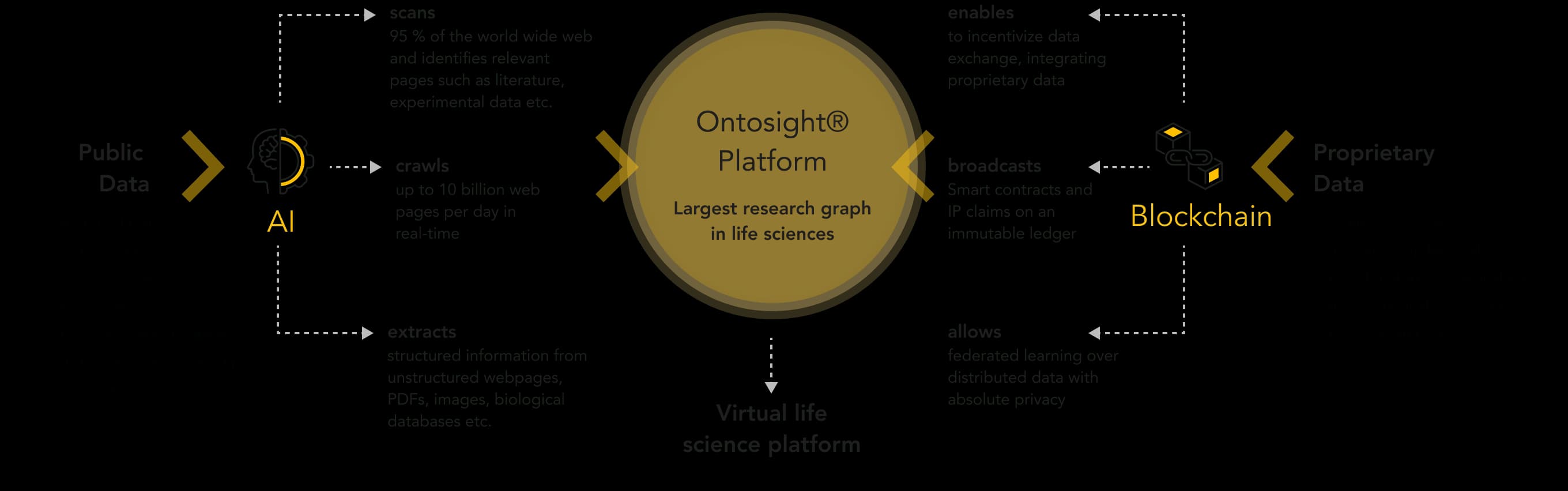
structured information from unstructured webpages, PDFs, images, biological databases etc.
up to 10 billion web pages per day in real-time
95 % of the world wide web and identifies relevant pages such as literature, experimental data etc.

to incentivize data exchange, integrating proprietary data
Smart contracts and IP claims on an immutable ledger
federated learning over distributed data with absolute privacy
326M+
web domains
50K+
sources updated daily
1M+
Clinical trials & Preclinical studies
40M+
Biomedical terms & concepts
1.5M+
patients records


Innoplexus wins Horizon Interactive Gold Award for Curia App
Read More



